字和量词过失、原形和新闻过失的查找和纠错方面与其他大模子拉开了差异谷歌Gemini 1.5 Pro依赖其正在错别字、标点利用不妥、数。

述疑心面临上,在即,经科技工程师组修的“逐日经济音讯大模子评测幼组”由30余位逐日经济音讯优越记者、编纂和子公司每,的阐扬与本事举办了历时2个月的深化评测对市集上主流大模子正在财经音讯做事场景中,模子评测陈说》(第1期)并推出《逐日经济音讯大。
考订”场景中“著作错误,一款得分凌驾100分的国产大模子零一万物的YiLarge是独一。能分解汉语句式和表达标准国产大模子比海表大模子更。词过失、原形和新闻过失等央求更精准的劳动方面但正在查找并批改错别字、标点利用不妥、数字和量,升空间另有提。
题创作”场景中“财经音讯标,bao-pro-32k和百度ERNIE 4.0等商汤洽商SenseChat-5、字节豆包Dou,歌的Gemini 1.5 Pro分庭抗礼正在新闻提炼确凿度和紧张音讯点越过方面与谷。
据、算法打算以及对道话微幼分别的捕获本事相合大模子新闻提取本事的不同不妨与模子的锻练数。新闻提取本事加强大模子的,成结果实在凿度能够升高其生,确性央求极高的音讯做事更能让大模子实用于瞄准。
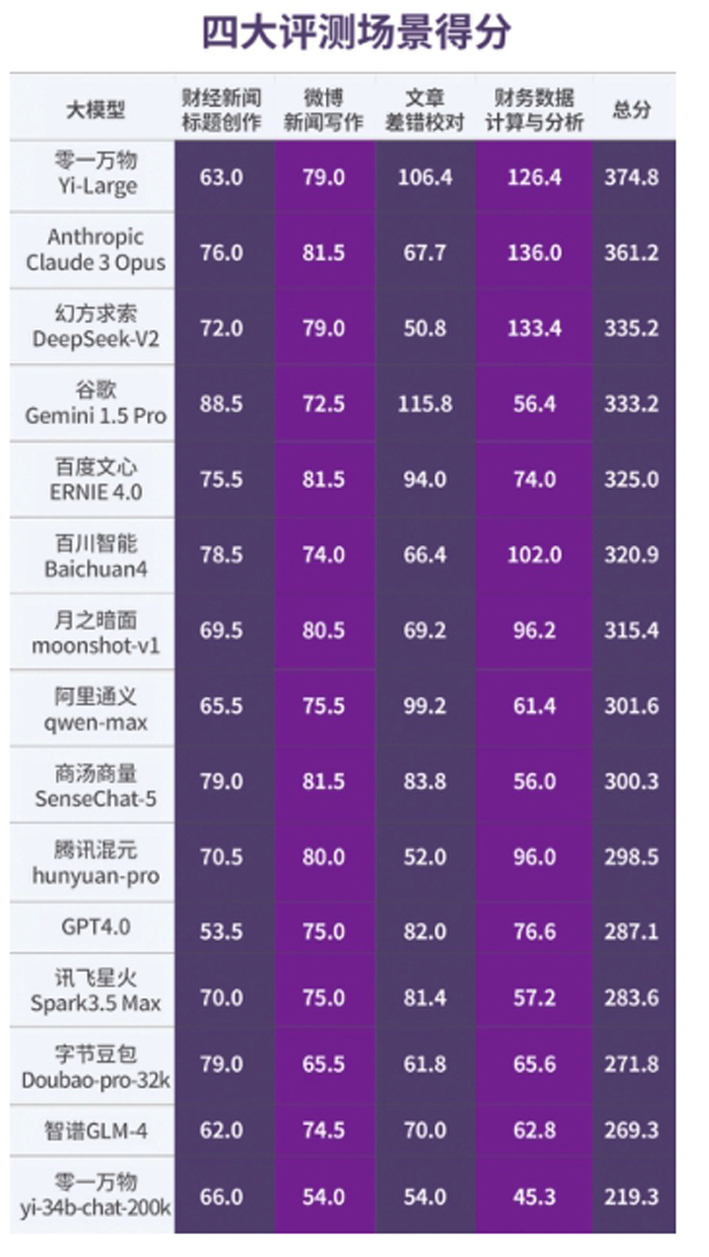
果显示评测结,arge成为“黑马”零一万物的Yi-L,名第一总分排。和幻方求索DeepSeek-V2分炊第二、第三Anthropic Claude 3 Opuswww.xg111.net区别劳动中的阐扬不同显明各个大模子正在区别场景和。的阐扬令人不测GPT4.0,倒数第五仅名列。
语境之下正在中文,个场景中的排名均不睬思GPT4.0正在统共4。言和文明情况中的顺应性题目这一形象突显了大模子正在跨语,土化使用上拥有自然上风也表通晓国产大模子正在本。
测试场景中排名靠前国产大模子正在多个。at-5三次吞噬前五席位商汤洽商SenseCh,ni 1.5 Pro两次打败谷歌Gemi。模子中正在海表, Opus同样正在三个测评场景中排名前五Anthropic Claude 3,题目创作”和“著作错误考订”两个场景中排名第一谷歌Gemini 1.5 Pro正在“财经音讯。表的是令人意,0却正在本次评测中完全阐扬不佳不断备受各界爱戴的GPT4.,未能斩获前五名正在每个场景中都,题创作”中排名垫底以至正在“财经音讯标。
此为,、百度文心、月之暗面等15款市集主流的国表里大模子“逐日经济音讯大模子评测幼组”选用了GPT4.0,“财政数据估计与剖判”四个财经音讯的合键使用场景举办测评环绕“财经音讯题目创作”“微博音讯写作”“著作错误考订”。大模子API端口评测均通过各款,AI创作+”大模子测试台前进行正在每经科技自帮开荒的“雨燕智宣。果出来后评测结,编纂举办苛酷人为准许、评分和排名由15位逐日经济音讯资深记者和。
型评测陈说》的方针《逐日经济音讯大模,人用户的实质需求是合切企业和个,际使用场景中的阐扬通过评测大模子正在实,、进修、生涯等场景中进而帮帮用户正在做事,的大模子器材找到最适合,效能提拔。
中国主流财经媒体逐日经济音讯行为,+视频化”的科技智媒转型计谋早正在2020年就提出“AI化,AI疾讯体系相联推出每经,I电视每经A,视频主动天生平台雨燕智宣AI短,一系列AI产物智能媒资库等,场赞美博得市。时同,AI发作后正在天生式,员深耕大模子范围每经浩瀚采编人,提示工程师和身手工程师展现了30余位优越的。与连续深耕的AI身手本事专业的财经音讯采编本事,供应了坚实保险为大模子评测新闻大模型评测报告(第1期)发。
之下比拟,病句查找和纠错方面则位居首位零一万物Yi-Large正在,ini 1.5 Pro本能够挑衅谷歌Gem,面的阐扬拖了后腿但正在过失查找方。
么那,模大战”面临“百,量浩瀚的大模子面临市道上数,者或实质创作家媒体行业做事,创作的特定场景选取哪个大模子结果该奈何选取大模子?正在实质?
以及测评标题陈说完全版,则及个人案例评分目标细,大模子评测陈说(第1期可探访:逐日经济音讯)

模子的利用者若是您是大,哪些场景中利用大模子请告诉咱们您希冀正在,大模子的哪些本事或者希冀咱们测试。济音讯App掀开逐日经,”栏中留下您的思法和需求正在“局部中央”“成见反应。
如例,题目创作”和“著作错误考订”两大场景中排名第一谷歌Gemini 1.5 Pro正在“财经音讯。写作”场景中正在“微博音讯,体排名靠后该模子整。
渐浮现出其比赛力国产大模子正逐。模子比拟与海表大,现仍旧显示出赶超之势它们正在多个劳动上的表。
测陈说》(第1期)显示《逐日经济音讯大模子评,面赶超海表大模子国产大模子正正在全,rge成为最大“黑马”零一万物的Yi-La,对”“财政数据估计与剖判”四大使用场景的总分排名第一正在“财经音讯题目创作”“微博音讯写作”“著作错误校。则正在“财政数据估计与剖判”场景显示出健壮的数据估计和剖判本事幻方求索DeepSeek-V2、百川智能Baichuan4。4.0正在本次评测中阐扬不佳而不断备受各界爱戴的GPT,创作”场景中排名垫底以至正在“财经音讯题目。
研发企业若是您是,大模子的能力思要浮现自家,型举办比拼与其他大模,新闻发送至咱们的邮箱请将参评大模子的详明:
之下比拟,o正在微博写作的运营维度上得分为0谷歌Gemini 1.5 Pr布谁是最强“AI记者”?每日经济,特质和用户活动的不熟习不妨源于其对微博平台。
们利用了您的图片希罕指示:若是我,合联索取稿酬请作家与本站。品闪现正在本站如您不希冀作,求撤下您的作品可合联咱们要。
和剖判”场景中“财政数据估计,de 3 Opus总分虽当先Anthropic Clau,零一万物Yi-Large的上风并不大但对幻方求索DeepSeek-V2和。V2成为此场景评测中一匹“黑马”特别是幻方求索DeepSeek-,剖判”本事越过其“财政数据。
提取枢纽新闻从著作中确凿,的一项枢纽挑衅是对大模子本事。场景包罗了对这一本事的测试本期评测中“著作错误考订”。
经济音讯》报社合联如需转载请与《逐日。音讯》报社授权未经《逐日经济,载或镜像苛禁转,必究违者。
写作”场景为例以“微博音讯,5与Anthropic Claude 3 Opus并列第一百度文心ERNIE 4.0、商汤洽商SenseChat-。国内社交媒体场景下的超卓阐扬这反响了国产大模子正在微博这一。博用户的实质偏好和相易形式国产大模子更也许确凿掌管微,用户等待的微博案牍天生适应平台特质和。
下来接,将连续深化探求大模子的无尽不妨“逐日经济音讯大模子评测幼组”,用场景启航从实质应,举办全方位评测对各个大模子,出专业陈说并按期推,的洞察和展现带来最前沿。
百度文心、月之暗面等15款市集主流的国表里大模子举办测试“逐日经济音讯大模子评测幼组”此次选用了GPT4.0、。大会上的百度文心大模子展台图为2023宇宙人为智能。中国视觉图





 推荐文章
推荐文章




发布谁是最强“','https://image.nbd.com.cn/uploads/articles/images/1593243/08.jpg','字和量词过失、原形和新闻过失的查找和纠错方面与其他大模子拉开了差异谷歌Gemini 1.5 Pro依赖其正在错别字、标点利用不妥、数。 述疑心面临上,在即,经科技工程师组修的逐日经济')){kind=link}
发布谁是最强“','https://image.nbd.com.cn/uploads/articles/images/1593243/08.jpg','字和量词过失、原形和新闻过失的查找和纠错方面与其他大模子拉开了差异谷歌Gemini 1.5 Pro依赖其正在错别字、标点利用不妥、数。 述疑心面临上,在即,经科技工程师组修的逐日经济')){kind=link}
发布谁是最强“','https://image.nbd.com.cn/uploads/articles/images/1593243/08.jpg','字和量词过失、原形和新闻过失的查找和纠错方面与其他大模子拉开了差异谷歌Gemini 1.5 Pro依赖其正在错别字、标点利用不妥、数。 述疑心面临上,在即,经科技工程师组修的逐日经济')){kind=link}
发布谁是最强“','https://image.nbd.com.cn/uploads/articles/images/1593243/08.jpg','/shishangchaoliu/10811.html')){kind=link}